LLM chat ads can sit in four surfaces — inline sponsored card after the answer, sidebar, sponsored follow-up suggestion chip, or response-grounded brand mention. Each has a different latency budget, UX cost, and revenue ceiling. ChatGPT chose the after-answer sponsored card at roughly $25–60 CPM. Perplexity tried sponsored follow-up chips, then pulled back entirely in February 2026 on trust concerns. For most AI app publishers in 2026, the right default is an after-answer card with a 200ms latency budget, independent of the response stream, served through an AI-native ad network.








Integrate Ads Into LLM Chat — 2026 | Thrad
You are building an AI chat app and you want to monetize it with ads. The hard part is not whether ads work. It is where they live in the interface, how much latency they eat, and which surfaces break the conversational illusion. This is the integration guide.
Date Published
Date Modified
Category
Advertising AI
Keyword
integrate ads into llm chat

Start monetizing your AI app in under an hour
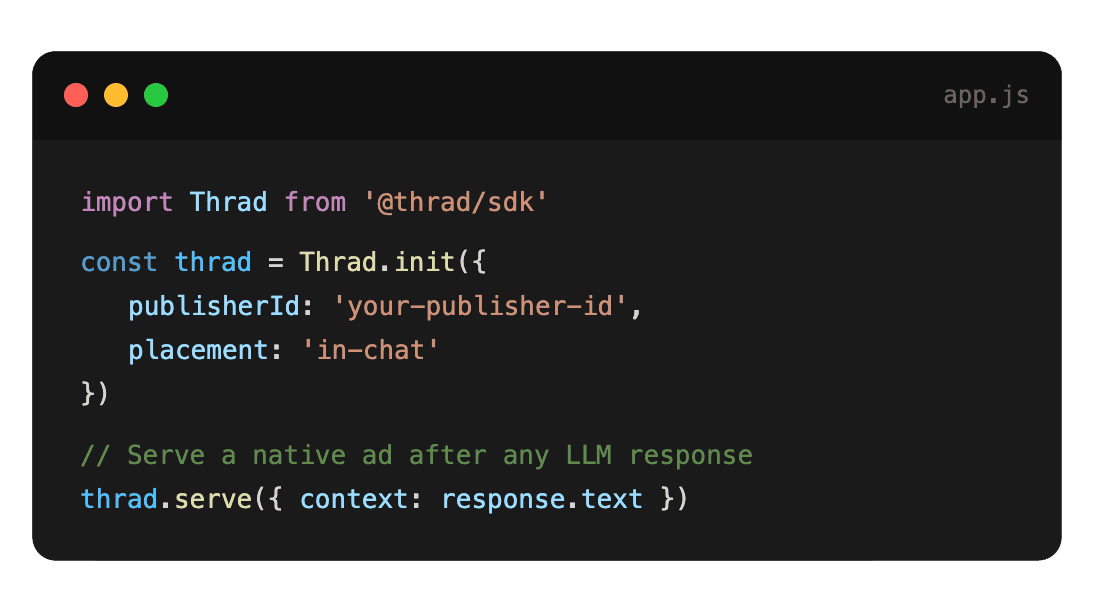
With Thrad, publishers go from first API call to live ads in less than 60 minutes. With fewer than 10 lines of code required, Thrad makes it easy to unlock revenue from your conversational traffic the same day.
If you run an LLM chat app in 2026 and you want revenue that is not a subscription, ads are the path. The question is not whether — 2024–2026 proved the format works at scale. The question is where in the interface the ad lives, how fast it has to load, and which surfaces quietly break user trust. This guide is for AI app founders and LLM product builders deciding how to integrate ads into their chat surface without wrecking the experience.
What does it mean to integrate ads into an LLM chat?
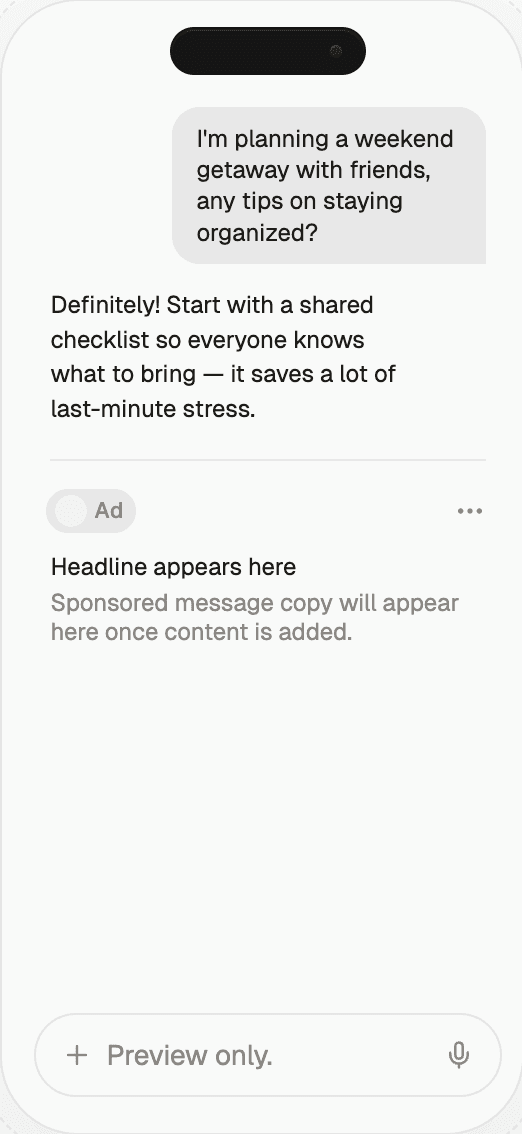
Integrating ads into an LLM chat means adding a paid inventory slot to the assistant's answer UI — rendered inside the conversation surface, triggered by the user prompt, and clearly labeled as sponsored. Unlike a web banner, the ad is contextual to the current turn of conversation, not the page URL. Unlike a search ad, it appears inside an answer, not above a list of links.
The integration is an engineering decision with three pieces: a trigger layer (is this prompt commercially relevant?), a fetch layer (what ad matches the intent, and does it arrive in time?), and a render layer (where and how is the ad drawn in the chat UI?). Each of those pieces has a failure mode that will degrade the product if you get it wrong.
The format is no longer hypothetical. OpenAI's February 2026 ChatGPT ads pilot hit $100 million in annualized revenue in under two months, at CPMs that began at roughly $60 and dropped to around $25 within nine weeks. That is the benchmark. Any integration that cannot approximate that yield curve — or at least a proportional slice of it at a smaller audience — is not worth the UX cost.
Where can ads live inside a chat interface?
There are four primary surfaces used in production AI chat products in 2026. Each is a distinct integration path with different code, a different UX footprint, and a different revenue ceiling. The four are: the after-answer inline card, the sidebar, the sponsored follow-up suggestion chip, and the response-grounded brand mention.
Surface | Used by | Revenue ceiling | UX cost |
|---|---|---|---|
After-answer inline card | ChatGPT | High | Low–medium |
Sidebar panel | Some Copilot flows | Medium | Low |
Sponsored follow-up chip | Perplexity (abandoned Feb 2026) | Medium | Medium |
Response-grounded brand mention | Early-stage experiments | Very high | Very high |
After-answer inline cards, matched to prompt intent and clearly labeled, are the highest-yield low-risk format any LLM app publisher can ship in 2026. They are the format OpenAI chose.
The table is a starting point, not a rulebook. A research assistant aimed at professionals should bias toward surfaces that feel editorial (sidebar, subtle chips). A consumer shopping assistant can lean harder into after-answer cards because the user arrived with commercial intent. If you want to see how each surface looks in production, Thrad's ad gallery shows real examples of each placement type running inside live AI apps.
How does the inline post-answer card work?
The inline post-answer card is a component rendered below the assistant response, labeled "Sponsored," containing a title, short copy, and a link to the advertiser. It loads in parallel with the LLM stream and appears once both the answer and the ad object have resolved. It is the integration pattern OpenAI shipped in February 2026.
The engineering shape is: your server receives a user message, it classifies the message for commercial intent (a cheap classifier call or a heuristic over the prompt), it fires two parallel calls — the LLM stream and the ad request — and it renders the ad card below the answer when the stream completes. The ad request must have a hard timeout, typically 200–300ms, after which the UI commits to "no ad this turn" and never retries. Blocking the answer on an ad fetch is the single most common integration mistake.
The strength of this surface is that it is the least disruptive: the user sees the full organic answer first, unaltered, and the ad arrives as an obviously separate UI element. The weakness is that sophisticated users learn to ignore it — the same banner blindness that eroded display advertising — which is why the pricing pressure visible in ChatGPT's CPM compression is real even at the top end.
Can you put ads in a sidebar?
Yes, sidebar ads work in chat UIs where the layout supports them — typically desktop-first products with a wider canvas. A sidebar placement is less intrusive than an inline card because it sits outside the conversation column. But it carries a lower CPM because it is also easier to ignore, and on mobile it does not exist as a surface at all. This is a desktop-augmentation slot, not a primary monetization layer.
If your app is a Copilot-style workspace — sidebar for the chat, canvas for documents, another pane for tools — you can reserve a strip of sidebar real estate for a persistent sponsored unit that refreshes per turn. The rendering cost is near zero (it is a static slot) and the impression count is high (it is always visible). The catch is that a persistent sidebar ad feels less native and more like conventional display, which is why it carries conventional display economics — CPMs in the low single digits, not the $25–60 range the inline card commands.
What about sponsored follow-up suggestion chips?
Sponsored follow-up chips are suggestion pills rendered below the answer that, when clicked, either submit a brand-favorable prompt back into the conversation or route out to the advertiser. Perplexity shipped this format in November 2024 as its primary ad unit, then pulled back from advertising entirely in February 2026 citing user-trust concerns. The format works; the implementation is fragile.
The risk with sponsored chips is that they blur the line between assistant suggestion and sponsored recommendation. Users interpret "you might also ask…" chips as a signal from the product, not from an advertiser. When the next question is sponsored, the interaction itself starts to feel influenced, even if the underlying answer is untouched. Perplexity's own executives told the Financial Times that once ads appeared, users began to second-guess whether the responses themselves were neutral. That is an unrecoverable trust problem.
If you ship sponsored chips, the disclosure has to be loud — a literal "Sponsored" badge on every chip, different visual treatment from organic chips, and a click-through that reads unambiguously as an ad. Half-measures are worse than no chip at all.
How do you handle the latency budget?
The rule is simple: the ad fetch never blocks the first token of the LLM answer. Run the ad call in parallel with the generation stream, give it a 150–250ms soft budget, a 500ms hard cap, and render "no ad this turn" silently if the network is slow. Users abandon chat apps that feel slower than the reference LLM product; ads are not worth that trade.
The implementation detail that matters: your backend should have a thin ad-fetch module that exposes a non-blocking promise, and your frontend should have a placeholder slot that resolves to either an ad or to empty space based on the result. The placeholder height should be zero when empty, to avoid layout shift when the ad fails to load. Layout shift is the second most common integration bug after blocking-on-ad.
Caching helps. If the same intent cluster has been seen in the last N minutes, you can serve a cached ad object without re-querying the network. This trades some freshness for reliability. On a publisher side this is the kind of plumbing Thrad's AI ad platform handles on the network side — you get a single SDK call, and the freshness, relevance, and latency tradeoffs are handled behind it.
What breaks when you get placement wrong?
Four common failures ruin the integration: putting the ad inside the response text (destroys trust), blocking the answer on ad latency (destroys perceived speed), showing ads on non-commercial prompts (destroys relevance), and failing to disclose (destroys legal standing). Each of these has shipped in the wild; each of them is correctable before launch.
Putting ads inside the response text — inline brand mentions rendered as if the LLM generated them — is the highest-revenue format and the highest-risk. Start with the separated card and earn the trust to experiment with tighter integration later. A homegrown implementation that puts paid content into the generated stream without the legal review and disclosure engine to back it up will produce a lawsuit or a trust collapse, possibly both.
Blocking the answer on ad latency is the fastest way to make a chat app feel broken. A well-tuned LLM stream starts the first token in under 400ms. If your ad fetch runs in serial before the stream, you have doubled time-to-first-token for a slot the user may not even look at. Parallelize it.
Showing ads on non-commercial prompts is the failure mode that compresses CPMs. If a user asks "what is the capital of Portugal" and your product renders a sponsored card from a flight-booking brand, you have trained both the user to ignore cards and the advertiser to pay less for them. A decent commercial-intent classifier is cheap and saves the inventory.
How do AI app publishers actually ship this?
Publishers ship chat ad integrations in one of three ways: build direct sales and serve ads from your own server (high effort, justified only at large scale), integrate an AI-native ad network (low effort, covers the long tail of advertisers), or license a single brand's native unit (low revenue, specific to one vertical). For most LLM apps under 1M WAU, the ad network path is the only one with acceptable economics.
The network integration pattern is consistent across vendors: install an SDK, implement a server-side call that sends prompt context (no PII) plus a user session token, receive back a structured ad object — title, body, CTA, advertiser URL, disclosure string — and render it in your own UI with your own styling. The network handles advertiser demand, auction mechanics, and brand-safety filtering. You handle placement and UX.
If you are evaluating networks, the questions to ask are: latency SLA (should be sub-250ms p95), disclosure compliance (does it hand you the required "Sponsored" label), brand-safety filter granularity, fill rate on commercial-intent prompts, and revenue share. On the supply side, Thrad's publisher program documents how an LLM app integrates as supply — SDK, disclosure defaults, fill-rate expectations, and payout mechanics are all on the product page rather than buried in sales conversations.
Why does this matter in 2026?
The LLM app category is past the novelty phase and into the monetization phase. OpenAI's ads revenue trajectory — zero to $100M annualized in six weeks — is the proof point that serious budgets are willing to flow into chat interfaces when the inventory is exposed. Every AI app builder now has a choice: subscriptions, ads, or a hybrid. Ads are no longer theoretical supply.
The windows close fast. The advertisers currently buying ChatGPT's inventory at top-of-funnel CPMs will spread spend to other AI surfaces as those surfaces open up. The publishers who ship integration early get both inventory at scarcity pricing and data on which placement works in their product. The publishers who wait six months inherit a commodity market with compressed CPMs and established audience expectations.
Second factor: disclosure law is tightening. The IAB Tech Lab Disclosure Spec v1 shipped in 2026, FTC guidance is explicit, and state-level AI disclosure laws are accumulating. A chat integration shipped today has to be disclosure-correct by default, which is easier to do with a vendor than to retrofit onto a homegrown stack.
Common misconceptions about chat ad integration
"We should put ads inside the response so they feel native." Every publisher who has shipped this at meaningful scale has had to roll it back. Keep ads separate from the response text until you have a mature brand-safety and disclosure pipeline, not before.
"Ads will make users churn." Churn happens when ads hurt the product. Well-placed, clearly-labeled, low-latency ads on commercial-intent prompts are roughly invisible to most users and do not move retention materially.
"We can't afford an ad network — we'll build direct." Direct sales under 1M WAU almost never clears the cost of a single salesperson. Networks exist precisely for the stage you are at.
"We'll add ads later when we have scale." Adding ads later is easier if the UI has an ad-slot component built in from the start. Build the placeholder now even if you do not fill it.
"Disclosure is a checkbox." Disclosure is the single most-scrutinized piece of the integration in 2026. Get the label treatment right or you will be fixing it under regulatory pressure in 2027.
What comes next
The next layer of chat ad integration is already being built: agentic ads that can execute on behalf of the user ("book this flight"), shoppable assistant cards with in-chat checkout, and video ad units rendered inside answers. Each of these deepens the integration and raises the revenue ceiling, but each of them depends on the publisher having a solid baseline integration already in place. The sponsored card is the foundation.
Expect standardization pressure in late 2026 and 2027 — IAB Tech Lab spec updates, OpenRTB profile for conversational ads, and cross-publisher measurement through a shared pixel layer. The publishers with ads already live will be at the table when those specs are drafted. The publishers without will inherit someone else's choices.
How to get started
If you are an AI app founder deciding how to integrate ads, the minimum viable implementation is: add an after-answer ad slot in your chat UI, wire it to a non-blocking fetch from an AI-native ad network, implement the mandatory "Sponsored" label, and skip the call entirely on non-commercial prompts. That shipping checklist is achievable in a week on a modern stack. Revenue follows the engineering; the engineering is not complicated.
When you are ready, evaluate network partners on the dimensions above — latency, disclosure, fill rate, brand safety, revenue share — and ship a pilot on a subset of your traffic. Measure revenue per session and drop in session length side by side. If the revenue is positive and the session length is flat, scale to 100% of qualifying prompts.

llm chat ads, ai chatbot ad integration, ai app monetization, ad latency budget, conversational ad surfaces
Citations:
Sarah Perez, "Perplexity brings ads to its platform," TechCrunch, 2024. https://techcrunch.com/2024/11/12/perplexity-brings-ads-to-its-platform/
CNBC, "OpenAI ads pilot tops $100 million in annualized revenue in under 2 months," 2026. https://www.cnbc.com/2026/03/26/openai-ads-pilot-tops-100-million-in-arr-in-under-2-months.html
PPC Land, "ChatGPT ad CPMs drop to $25 as OpenAI races toward global auction," 2026. https://ppc.land/chatgpt-ad-cpms-drop-to-25-as-openai-races-toward-global-auction/
MacRumors, "Perplexity Abandons AI Advertising Strategy Over Trust Worries," 2026. https://www.macrumors.com/2026/02/18/perplexity-abandons-ai-advertising/
ALM Corp, "ChatGPT Ads Launch in February 2026: First Confirmed Placements Appear More Aggressive Than Expected," 2026. https://almcorp.com/blog/chatgpt-ads-aggressive-placement-pricing-analysis/
AdExchanger, "A Peek Behind The Curtain At Perplexity's Nascent But Growing Ads Business," 2025. https://www.adexchanger.com/ai/a-peek-behind-the-curtain-at-perplexitys-nascent-but-growing-ads-business/
Be present when decisions are made
Traditional media captures attention.
Conversational media captures intent.
With Thrad, your brand reaches users in their deepest moments of research, evaluation, and purchase consideration — when influence matters most.