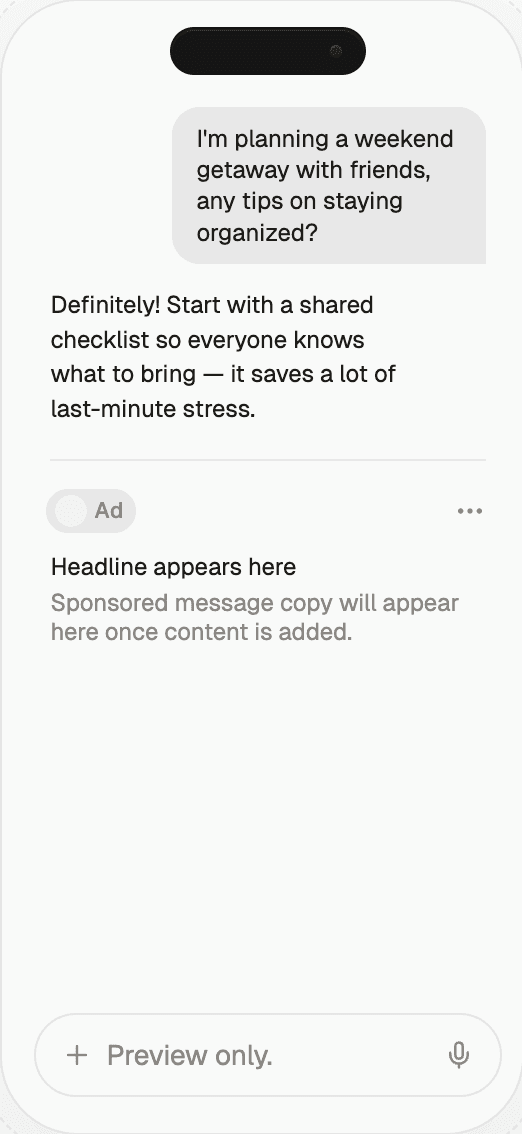
Evaluate an ad SDK for an LLM app on six axes: integration effort, UX control, latency overhead, revenue share, brand safety, and measurement depth. No SDK wins on all six. Prioritize latency and UX control for retention-sensitive products; prioritize revenue share and measurement for apps with volatile traffic. Run a pilot with two vendors before committing.








Choosing an Ad SDK for LLM Apps — 2026 Guide | Thrad
Picking an ad SDK for an LLM app is one of the most consequential architecture choices a founder makes in the first 18 months. Wrong pick: the SDK bleeds latency, degrades UX, or creates a brand-safety fire drill. Right pick: the free tier pays for itself. This is the evaluation framework and checklist we'd run through ourselves.
Date Published
Date Modified
Category
Publisher Monetization
Keyword
ad sdk for llm apps

Start monetizing your AI app in under an hour
With Thrad, publishers go from first API call to live ads in less than 60 minutes. With fewer than 10 lines of code required, Thrad makes it easy to unlock revenue from your conversational traffic the same day.
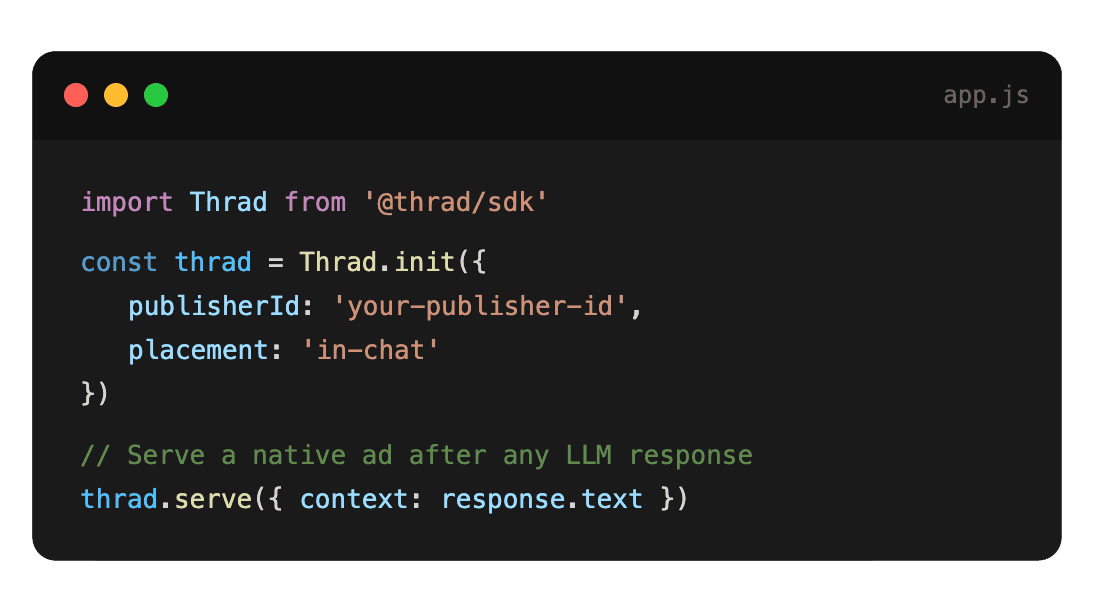
Picking an ad SDK is one of the most consequential architecture decisions an LLM app founder makes in the first 18 months after shipping a free tier. The wrong pick costs you latency, degrades UX, or creates a brand-safety fire drill. The right pick pays for the free tier without users noticing. This is the evaluation framework we'd use ourselves — six axes, a concrete checklist, and the two-week pilot protocol that keeps the decision reversible.
What is an ad SDK for an LLM app?
An ad SDK for an LLM app is a library (or API) an AI app founder integrates to render sponsored placements inside AI responses. It handles prompt classification, auction, creative rendering, and disclosure, then reports measurement back to the publisher. Thrad's ad platform for AI-app publishers is one such integration; Sponsored.so, Teads LLM, Koah Labs, and several others ship similar libraries with different opinions about placement, rev share, and safety policy.
The SDK's job is to be a clean interface between your product and the demand side of the AI ad network. What you pass in: the user prompt, context, maybe the model response. What you get back: an ad-augmented response, an ad payload your UI renders, or a no-op when the prompt isn't safe to monetize. The quality of that interface — how clean, how fast, how controllable — is the SDK's product.
Why is SDK choice so consequential?
Because the SDK sits in the hot path of every single prompt, and every prompt is a user interaction. Latency, response quality, and brand safety all run through the SDK. A bad pick shows up as a slower product, weirder outputs, or a screenshot on social media for the wrong reasons. Three risks specifically:
Latency bleed. If the SDK adds 400ms to a 1.2s response, that's
a 33% slowdown on the critical path. Users notice.UX degradation. Ads that don't match, don't disclose, or
interrupt the conversational flow train users to dismiss your
product.Brand-safety exposure. The SDK that serves an off-topic or
policy-violating ad in a viral screenshot costs you more than a
quarter of ad revenue to recover from.
The SDK sits in the hot path of every prompt. Its latency, its UX posture, and its safety policy are product decisions disguised as integrations.
The upside is just as concrete. Business of Apps tracks $3B in 2025 generative AI app revenue, and the ChatGPT-scale publisher surface means demand-side budgets for AI-native placements have grown the denominator meaningfully. An SDK that converts your free-tier traffic at $15–$50 RPM turns your monetization model from "raise another round" to "fund product with cashflow."
What are the six evaluation axes?
Six axes matter. Rank them by your product constraints — a latency-sensitive companion app weights latency and UX first; a high-volume affiliate chatbot weights rev share and measurement. No SDK wins on all six.
Axis | What to check | Failure mode |
|---|---|---|
Integration effort | Time to first ad, number of code changes | Multi-week integrations without clear upside |
UX control | Placement rules, disclosure defaults, category blocklists | Intrusive formats, no disclosure, category mismatch |
Latency overhead | Added ms on prompt classification + auction + render | >300ms added to a sub-second response |
Revenue share | Split, payout cadence, minimum threshold | Headline eCPM that hides low match rate |
Brand safety | Default-refuse categories, output-level checks, compliance | No refusal policy, all-or-nothing disclosure |
Measurement depth | Per-category RPM, raw logs, retention controls | Black-box dashboards, no exportable data |
Two meta-rules across all six axes. First, treat vendor claims as hypotheses to test, not statements to trust. Second, weight axes by how reversible they are — integration effort is reversible (you can rip out an SDK), but a retention hit from bad UX compounds for months.
How much integration effort should an SDK require?
One day to one week for a drop-in SDK or REST API. Two to six weeks for inline prompt-decoration integrations that modify your LLM call. Anything longer without a clear architectural justification is a red flag — the vendor is either immature or over-selling enterprise features you don't need in the MVP.
Concretely, the integration checklist:
Language coverage. Does the SDK exist for your stack (TypeScript,
Swift, Kotlin, Python)?Platform coverage. Web, iOS, Android, server-side?
Installation. Package manager install + two to five lines of
init code, or something heavier?Prompt-flow impact. Does it wrap your LLM call? Replace it?
Proxy it? The lightest touch is an after-call hook.Feature flag support. Can you ramp traffic 10% at a time?
Removal. If you decide to switch, what's the unwind cost?
Drop-in SDKs that hit all six cleanly are the cheapest to pilot. Ones that score poorly on "removal" are particularly dangerous — a vendor that's easy to install but hard to leave is a vendor that will eventually take a larger cut once you're locked in.
How does UX control differ between SDKs?
UX control is the highest-variance axis. Some SDKs are highly opinionated about placement and disclosure; others give the publisher full control but require explicit integration work for every format variant. Four sub-axes:
Placement rules. Inline, adjacent, below-the-response, modal,
or pre-prompt are the common options. Inline and adjacent are most
native; modal is most intrusive.Disclosure format. "Sponsored" label, inline disclosure in the
text, separate card with badge, or no disclosure at all (not
compliant). The first three are fine; the fourth is a compliance
disaster.Category blocklists. Can the publisher block specific advertiser
categories (alcohol, gambling, political, competitors)? Is the
blocklist effective pre-auction, or does it apply only after a
match?Fallback behavior. What renders when no ad wins? A blank? A
house ad? A soft suggestion? Clean no-op is best.
Thrad's ad gallery shows specific creative formats live on its network, which is the fastest way to evaluate native fit before signing. Spend 20 minutes mentally inserting each format into your app's chat flow. If any of them would embarrass you in a product review, the SDK isn't right for your surface.
How do you measure latency overhead?
Benchmark it. The vendor will quote a median number; your real distribution matters more. Specifically:
Integrate the SDK in a staging environment.
Run 1,000 representative prompts through the full pipeline —
prompt in, response out.Record p50, p95, p99 latency added by the SDK.
Compare against your baseline response latency without the SDK.
A rough target: the SDK should add less than 10% to your p50 and less than 20% to your p95. Over those thresholds, users start to notice. For prompt-decoration SDKs that modify your LLM call, also check token count and response quality — some SDKs inflate token usage by 10–30% through system-prompt injection, which eats into your API costs on top of the latency.
Latency added by an ad SDK is a product tax on every prompt. Under 10% at p50 is background noise; over 20% is a retention risk. Benchmark before signing, not after.
For client-side SDKs, network variability dominates the latency. Make sure the SDK supports async prefetch — classifying the prompt and resolving the auction while the LLM is still generating the response. That pattern hides most of the overhead behind the LLM's own generation time.
How should you evaluate revenue share?
Not on the headline eCPM alone. The numbers that matter are RPM (revenue per 1,000 prompts), payout cadence, and the terms beneath the split. Four questions to ask every vendor:
What's the split, gross vs net? Some networks take a cut pre-
split, so a "70%" publisher share can be closer to 55% of actual
advertiser spend once platform fees are netted out.What's RPM in my category at my volume? Reject averages. Ask
for bracketed estimates.Payout cadence and threshold. Net-30 vs net-60, $50 vs $500
minimum. This matters for cash flow.Contract renegotiation terms. Can you change SDK versions,
pause campaigns, or exit without penalty?
ChatAds uses a flat per-request API fee model that returns ~100% of affiliate commissions to publishers — favorable for high-intent traffic, risky for volatile traffic where the per-request fee can exceed earnings in a dry month. Rev-share models are friendlier to newer chatbots precisely because they never charge when they don't earn. Choose based on which cash-flow shape you can actually underwrite.
How does brand safety show up at the SDK layer?
It shows up as defaults you inherit and overrides you control. The SDK has two jobs: refuse to match on unsafe prompts (input safety) and suppress unsafe renders after the LLM responds (output safety). Most SDKs handle input safety reasonably well; output safety is where maturity varies.
Input safety checks. Does the SDK refuse on crisis, minors,
medical-emergency, regulated-financial, and political prompts by
default? GARM alignment is the 2026 baseline.Output safety checks. If the LLM's response takes an unsafe
turn after auction, does the SDK pull the ad pre-render? Or does
it commit at auction time and ship whatever the model said?Publisher overrides. Can you add app-specific blocklists
(competitors, categories your brand avoids)? How fast do changes
propagate?Audit logs. Are the matches logged with the prompt category
and advertiser identity, exportable for internal review?Compliance coverage. Does the SDK help with FTC disclosure,
EU AI Act disclosure, and vertical-specific rules (HIPAA-adjacent
content, SEC suitability for financial advisors)?
Thrad's infrastructure page documents the safety layer at the marketplace level — refusal categories, output checks, exportable audit logs. Compare any other vendor's policy against that baseline. A vendor that can't match or exceed the baseline on safety is handing you compliance risk in exchange for revenue you wouldn't accept on other terms.
How deep should measurement go?
Deep enough that you can debug a bad week. Three capabilities:
Per-category revenue reporting. Which intent categories make
money in your app? Travel vs finance vs general research vs product
shopping? Without this breakdown, you can't steer product
decisions.Exportable logs. Prompt → classification → auction → match →
render → click → conversion. Exportable, not dashboard-only.Retention controls. A built-in holdout cohort that never sees
ads, so you can measure the true UX cost. Some SDKs include this;
for others you'll run it yourself with feature flags.
Black-box dashboards are a red flag. A network that won't give you raw data is a network you can't renegotiate with — because renegotiation requires evidence, and evidence requires data access.
What's the right pilot protocol?
A two-vendor, two-week, feature-flagged pilot. The structure:
Shortlist two SDKs. Pick based on the six axes above. Pick
candidates that differ — e.g., a conversational-native SDK and an
affiliate-first SDK — so the pilot is informative about the model
choice, not just the vendor.Integrate both behind feature flags. Route 10–25% of traffic
to each, hold out 10–25% as a no-ad control.Run for two weeks minimum. This covers weekday and weekend
traffic mix and gives enough data for statistical significance on
retention deltas.Measure four numbers. RPM, match rate, added latency (p95),
and 7-day retention delta vs control.Score. RPM × (1 − retention delta) is the single scalar that
rewards networks that make you money without hurting the product.Decide. The winner becomes primary. If you're over 50k daily
prompts, the runner-up becomes your fill partner.
Document the decision. Pilot outcomes fade fast from memory, and the next time you're re-evaluating, you want the data. This matters because SDK switching is quarterly-cycle work once you've shipped — you'll do it at most every few quarters, so each decision compounds.
Common misconceptions
"Higher eCPM SDK = more revenue." No — RPM (eCPM × match rate)
is what lands. Networks that report only eCPM are obscuring the
denominator."I can evaluate an SDK from the docs alone." You can shortlist
from docs. You can't evaluate. Pilot is the only honest signal."Latency doesn't matter for chat — users expect a pause."
Users tolerate the LLM's latency. They don't tolerate additional
latency from an ad SDK they didn't ask for."Brand safety is the vendor's problem." The vendor sets defaults;
you set category overrides. Both fail publicly if one side is
sloppy."Building in-house is cheaper long-term." Not under a few
million prompts per day. Engineering cost of demand relationships,
classification, disclosure, and measurement exceeds revenue lift at
smaller scale.
What comes next for LLM app ad SDKs?
Three shifts through late 2026 that will change how an LLM app founder thinks about SDK choice:
IAB interoperability. A shared spec for auction, classification,
and disclosure will make dual-SDK setups cheaper. Header-bidding-
style waterfalls will become standard rather than custom.On-device classification. Moving prompt classification to the
client reduces latency and improves privacy. Early-mover SDKs are
shipping this in 2026; by 2027 expect it as table stakes.Revenue attribution bridges. Third-party measurement providers
will ingest SDK events alongside display and CTV, so LLM-app
publishers will finally have attribution stacks they can show a
brand advertiser. Publishers with exportable-log SDKs benefit
disproportionately.
None of these shifts change the core evaluation framework. They do reward publishers who integrate SDKs such that switching, adding, or upgrading is a configuration change — not a rewrite.
How to get started
Write the shortlist. Pick two vendors whose axes-profile matches your constraints (latency-sensitive, rev-sensitive, brand-safety-sensitive, depending on product shape). Implement each behind feature flags in a day. Run the two-week pilot. Compute RPM × (1 − retention delta). Choose. Document the decision. Re-evaluate in two quarters.
If your LLM app is very early (under 10k daily prompts), simplify: pick one vendor on the fastest integration path and clearest safety defaults, ship, revisit when you have real volume. The cost of a slightly-suboptimal SDK at 10k prompts/day is trivial relative to the cost of burning two weeks running a pilot with no statistical power. If your LLM app is scaling (100k+ daily prompts), the pilot is worth running rigorously — the RPM difference between a good and a great SDK on that volume is real money.
The meta-advice: don't optimize the SDK choice in a vacuum. Optimize the SDK-plus-product. A $30 RPM SDK that shaves 2% off retention is worse than a $20 RPM SDK that's neutral on UX. The best SDK is the one your users don't notice — with the most revenue flowing behind the scenes. Everything else is a proxy for that.

llm sdk ads, ai app monetization sdk, conversational ad integration, chatbot sdk comparison, ad api for llm
Citations:
Sponsored.so, "Native AI Ad Platform for LLMs, Chatbots & Agents," 2026. https://sponsored.so/
Teads, "Getting Started with Teads LLM Integration," 2026. https://developers.teads.com/docs/Chatbot-AI-SDK/Getting-Started/
Vercel, "AI SDK by Vercel," 2026. https://ai-sdk.dev/docs/introduction
EthicalAds, "Developer Ad Network with AI-powered Contextual Targeting," 2026. https://www.ethicalads.io/
ChatAds, "6 Ad Monetization Platforms for AI Wrappers Compared (2026)," 2026. https://www.getchatads.com/blog/six-ad-monetization-platforms-for-ai-wrappers-compared/
Business of Apps, "AI App Revenue and Usage Statistics (2026)," 2026. https://www.businessofapps.com/data/ai-app-market/
TechCrunch, "ChatGPT reaches 900M weekly active users," February 2026. https://techcrunch.com/2026/02/27/chatgpt-reaches-900m-weekly-active-users/
IAB Hong Kong, "Navigating Brand Safety and Suitability in the AI Era," 2025. https://iabhongkong.com/adtecharticle202505
Be present when decisions are made
Traditional media captures attention.
Conversational media captures intent.
With Thrad, your brand reaches users in their deepest moments of research, evaluation, and purchase consideration — when influence matters most.