The 2026 generative AI advertising creative workflow runs six
stages: brief, brand spec, generation loop, human review gate,
measurement setup, and audit-trail publish. The bottleneck is almost
never the model. It is the brand spec on the front end and the
review gate in the middle. Teams that invest there ship 4–6x more
approved variants per week and cut legal escalations by roughly 70%.







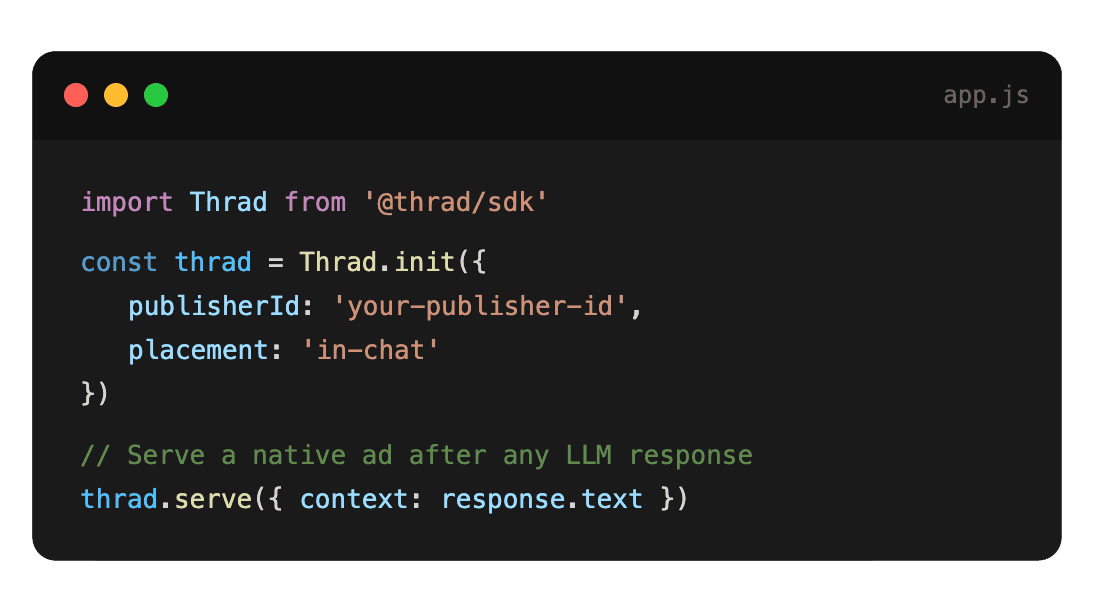
Start monetizing your AI app in under an hour
With Thrad, publishers go from first API call to live ads in less than 60 minutes. With fewer than 10 lines of code required, Thrad makes it easy to unlock revenue from your conversational traffic the same day.
Generative AI Ad Creative Workflows 2026 | Thrad
A working generative AI advertising creative workflow has six
stages, not one prompt box. The winning 2026 teams aren't the ones
with the best models — they're the ones with the cleanest brief, the
tightest brand spec, and the sharpest review gates.
Generative AI advertising creative workflows look simple on a slide —
prompt, generate, ship — and complicated in practice. The 2026 teams
shipping hundreds of approved variants a week have a six-stage
workflow and a disciplined review cadence. Every stage exists because
a previous generation of programs failed without it. This article walks
the stages in the order a campaign actually moves, names the failure
modes at each, and shows the operating-metric targets mature teams
hold themselves to. Whether you're standing up a first pilot or
rebuilding a program that stalled in review queues, the structure
below is the one that survives audit, scales to hundreds of variants,
and produces work the brand can defend.
What is a generative AI advertising creative workflow?
A generative AI advertising creative workflow is the end-to-end
pipeline that moves a campaign intent from brief to published,
trackable creative with AI generation inside the loop. It pairs a
model-driven production step with human-owned review, measurement, and
audit gates so a brand can ship at volume without losing control. The
six canonical stages are:
Brief. What is the campaign actually trying to do?
Brand spec. What rules must every output honor?
Generation loop. Prompt, produce, rate, revise.
Review gate. Named human accountability per asset.
Measurement setup. Tagging, experiment design, baselines.
Publish with audit trail. Every approved asset logged.
Teams that skip stages don't move faster — they move brittle. The
2026 Forrester creative-ops survey found that programs skipping the
brand-spec step produced roughly 3x more brand-safety incidents per
1,000 assets than programs that treated the spec as a first-class
deliverable. The six-stage model is not a theoretical ideal; it is
the minimum surface area that audit, finance, and brand reviewers
will accept on anything approaching meaningful spend.
Stage 1 — How do you write a brief that a model can actually use?
A good brief is crisp on audience, job-to-be-done, constraint, and
success metric. Generative AI doesn't change what a brief is; it
raises the cost of a bad one, because a fuzzy brief produces an
avalanche of fuzzy output faster than humans can review. Briefs that
fit on one index card outperform briefs that fill a deck because the
model — and the reviewer — can both hold them in working memory.
Practical rule: write the brief as one paragraph a model can ingest
directly, then attach the brand spec and measurement plan as separate
artifacts. A strong 2026 brief fits this shape:
Audience. One specific sentence. Not "millennials" — "iOS-first
professionals in tier-1 US cities who already use our competitor."Job. What state change are we causing? Sign-up, consideration
lift, repurchase?Constraint. The one thing the ad cannot be or say.
Metric. The one number we will grade this against.
Teams that adopt this template report first-pass approval rates in the
60–70% range, versus 20–30% on free-form briefs, according to the
2026 WARC Creative Operations benchmark. The difference compounds:
every asset that clears on its first review frees reviewer hours for
work that actually needs judgment.
Stage 2 — Why does the brand spec matter more than the model?
The brand spec is the most undervalued artifact in the 2026 stack.
Voice, tone, palette, approved talent, blocked imagery, regulated
claims, disclosure requirements, legal holds — all in machine-readable
form. Treat it like code: version-controlled, reviewed, diffable,
tested against sample outputs on every change. The spec is what turns
a general-purpose model into a brand-safe one.
A common failure is to keep the spec in a PDF. Brand specs in PDFs
don't constrain generation; brand specs in structured files do.
Leading 2026 programs store the spec as YAML or JSON with these
sections:
Section | What it contains | Change cadence |
|---|---|---|
Voice | Tone rules, banned phrasings, example phrases | Quarterly |
Visual | Palette hex values, type stack, composition rules | Quarterly |
Talent | Approved spokespeople and likenesses, blocked figures | Monthly |
Claims | Approved product claims, regulated language | Monthly |
Disclosures | AI-generation notices, jurisdictional rules | Monthly |
Blocklists | Prohibited topics, competitor names, reserved terms | Weekly |
The spec lives in the same version-control system as the generation
pipeline. Every asset carries a pointer to the spec version it was
produced under, which matters the moment a regulator or retailer asks
"what were the rules in March?"
Stage 3 — How should the generation loop work?
Generation in 2026 is rarely one-shot. The loop that ships is the loop
that rates and revises. A typical cadence:
Generate 8–12 candidates from a single prompt plus spec bundle.
A creative rates them against the brief and brand spec on a
structured rubric.Top 2–3 are revised with a sharper prompt and possibly a different
model.Loop 3–5 times until one clears the on-brief and on-brand thresholds.
The rating step matters more than the prompting step. Teams with a
structured rubric (on-brief 1–5, on-brand 1–5, fatigue risk 1–5)
converge 40–60% faster than teams with "does it feel right." The rubric
also makes training new reviewers tractable, because "why did this
asset fail?" becomes an auditable score rather than a private opinion.
A good 2026 loop produces one approved asset per 10–15 candidates on
mature campaigns and one per 30–40 on net-new concepts. The candidate-
to-approved ratio is itself a leading indicator: when it drifts past
50:1, the brief or brand spec needs attention, not the model.
Stage 4 — What does a functional review gate look like?
Named humans, named responsibilities, named SLAs. A review gate with
anonymous approvers dissolves into lowest-common-denominator output
because no individual bears reputational cost for a mediocre asset.
The 2026 Digiday operations survey placed "anonymous approval queues"
as the single strongest predictor of brand-safety incidents on AI-
assisted programs.
Roles at the gate:
Creative lead — signs off on concept fit. SLA: 4 business hours.
Brand reviewer — signs off on voice, palette, composition. SLA:
4 business hours.Legal/compliance — signs off on claims, disclosures, regulated
language. SLA: 1 business day.Measurement lead — confirms the asset is tagged, in the right
experiment cell, and traceable. SLA: same-day.
In regulated categories, add a category specialist (medical reviewer,
financial reviewer). In agency settings, add a client-side gate after
internal approval, with a separate SLA. Every gate needs a named
substitute so a single vacation doesn't stall the queue.
The fastest 2026 creative teams aren't generating faster — they're
approving faster. The review gate, not the model, is the rate
limiter. Fix the gate and everything upstream compounds.
Stage 5 — How do you wire measurement before generation?
Before anything publishes, the measurement plan is wired: control
group identified, lift method chosen, generative-surface tracking
configured where relevant. Creative that ships without a measurement
plan is a future case-study failure waiting to happen, because a
program that cannot prove lift is a program finance cannot refund.
The pre-flight measurement checklist:
Baseline committed. Pre-period, parallel cell, or geo hold-out
— pick one and write it down.Experiment design locked. Number of cells, duration, primary
metric, guardrails.Tracking instrumented. Every variant carries a unique ID that
flows through to conversion.Surface coverage mapped. For generative surfaces, decide which
citation monitors are in scope.Refresh trigger defined. At what lift decay do we swap
creative?
Teams that skip step five get caught flat-footed when a campaign
decays in week four with no refreshed inventory ready. Measurement is
not a post-campaign event; it is a pre-campaign artifact.
Stage 6 — What does a real audit trail contain?
Every approved asset needs a record: prompt, version, reviewer,
timestamp, brand spec version, model version, experiment cell. If the
brand is ever audited, challenged, or asked "why did this run," the
answer has to exist. The audit trail is also how a team debugs its
own decay: six weeks into a program, the question "which prompts
produced our top 10 variants" should be answerable in minutes.
Audit field | Why it matters | Retrieval deadline |
|---|---|---|
Prompt text | Regenerate + diagnose drift | 1 business day |
Model + version | Reproducibility, liability | 1 business day |
Brand spec version | Rule-set at time of generation | 1 business day |
Reviewer IDs | Chain of custody | 1 business day |
Timestamps | Sequencing disputes | Same day |
Experiment cell | Measurement reconciliation | Same day |
Disclosure text | Regulatory response | Same day |
Audit trails are not overhead. They are the only artifact that turns
an incident into a fixable problem rather than a brand crisis.
How do the six stages compare at a glance?
Stage | Common failure | Good-team fix | Target SLA |
|---|---|---|---|
Brief | Vague audience/goal | One-paragraph model-ingestible brief | 1 day |
Brand spec | Lives in a PDF | Structured, versioned, diffable | Quarterly refresh |
Generation loop | One-shot prompts | 3–5 rated revision loops | 4 hours |
Review gate | Anonymous approvers | Named roles with SLAs | 1 business day |
Measurement setup | Done after publish | Wired before generation | Pre-flight |
Publish + audit | No trail | Prompt + reviewer + version per asset | Real-time log |
Approval capacity, not generation capacity, is the 2026 constraint
on creative output. Measuring reviewer throughput is the single
most actionable operating metric a creative ops lead can adopt.
Common misconceptions
"Better prompts are the advantage." Better briefs and brand
specs are. Prompts are downstream of both. Invest the week in spec
engineering, not prompt tweaking."We'll add review later." Without a named gate from day one,
teams publish work they later regret and can't retract cleanly.
Retrofitting review onto a running program costs 3–5x what building
it in does."Audit trails are overhead." They are the only thing that turns
an incident into a fixable problem rather than a brand crisis."The model choice matters most." By 2026 multiple frontier
models produce passable creative. Differentiation is upstream in
brief quality and downstream in review discipline."One creative owns the full loop." That's a pre-AI pattern. In
2026 the loop owner is usually a creative-ops lead, and senior
creatives focus on brief, spec, and review judgment.
What comes next
Expect three shifts in 2026-2027. First, brand specs become vendor-
portable artifacts, with IAB Tech Lab and WFA interoperability drafts
already circulating; a brand will switch generation tools without
rebuilding guardrails. Second, review gates get tool support —
queueing, SLA tracking, and disagreement-resolution workflows — that
today lives in ad-hoc spreadsheets and shared channels. Third,
measurement will grow native generative-surface tracking into the
creative pipeline, so an asset's expected citation performance is
predicted before the creative ships, not measured six weeks after.
The common thread is that the stages stay. What changes is how much
of each stage is tool-supported versus human-coordinated. Teams that
have already formalized the six-stage workflow will slot the new tools
in cleanly; teams that haven't will try to buy their way out of
process debt and fail.
How to stand up this workflow
Pick one campaign. Write the brief as one paragraph using the
audience–job–constraint–metric template. Convert the brand PDF into a
structured YAML or JSON spec, starting with the five sections listed
above. Assign named reviewers with explicit SLAs and named
substitutes. Wire measurement before generation: baseline, experiment
design, tracking, refresh trigger. Log every approval with prompt,
reviewer, version, timestamp, spec version, and cell. Run the
campaign, measure, iterate, then codify the patterns that worked into
the spec for the next one.
Thrad sits at the measurement and publish end of this workflow — so
the audit trail you build at the review gate pairs with a measurement
view that actually reflects generative-surface exposure. That pairing
is how a creative program graduates from pilot to standing line item
in a 2026 marketing plan.

ai creative workflow, ai ad production pipeline, generative ad workflow, ai creative ops
Citations:
WARC, "Creative Operations in the AI Era," 2026. https://warc.com
IAB Tech Lab, "Generative AI in Advertising Standards v1," 2026. https://iabtechlab.com
Campaign, "Inside the new creative ops stack," 2026. https://campaignlive.com
Ad Age, "Why approval, not generation, is the real AI bottleneck," 2026. https://adage.com
Forrester, "The State of Creative Operations 2026," 2026. https://forrester.com
Digiday, "Brand spec documents move from PDF to code," 2026. https://digiday.com
Be present when decisions are made
Traditional media captures attention.
Conversational media captures intent.
With Thrad, your brand reaches users in their deepest moments of research, evaluation, and purchase consideration — when influence matters most.
Date Published
Date Modified
Category
Advertising AI
Keyword
generative ai advertising creative workflows