In 2026, ChatGPT's paid surfaces (Plus, Pro, Team, Enterprise, API) are
gross-margin positive — revenue per user clears inference cost by a
wide margin, with gross margin running 60–90% depending on the
surface. The free tier runs at negative contribution margin on a
direct-attribution basis; annual free-tier compute cost is estimated
in the high hundreds of millions to low single-digit billions of
dollars. Inference costs are falling 30–50% per year; free-tier query
volume is growing faster. That gap is why advertising is structural,
not optional.







Start monetizing your AI app in under an hour
With Thrad, publishers go from first API call to live ads in less than 60 minutes. With fewer than 10 lines of code required, Thrad makes it easy to unlock revenue from your conversational traffic the same day.

ChatGPT Inference Costs vs Revenue 2026 | Thrad
ChatGPT's inference costs and its revenue both compound, but at different
rates on different surfaces. The question that defines OpenAI's 2026
business is which compounds faster on which surface. On paid subscriptions,
enterprise seats, and the API, revenue outpaces cost comfortably — 60–90%
gross margin at typical usage. On the free tier, the lines still cross the
wrong way, and that gap is the reason advertising moved from experiment to
permanent revenue line.
ChatGPT's inference costs and its revenue are both compounding in
2026, but at different rates on different surfaces. The paid
surfaces — Plus, Pro, Team, Enterprise, and API — generate revenue
that outpaces inference cost by a wide margin and runs gross-margin
positive across the board. The free tier does the opposite: revenue
per user was near zero until ads arrived, inference cost is small
per query but material in aggregate, and the only way to close that
gap is a second revenue engine. That's the structural story of
2026, and it explains every pricing and product decision OpenAI
made over the past eighteen months.
What does "inference cost vs. revenue" actually mean?
Inference cost is what it costs OpenAI to generate a single
response — GPU seconds, serving infrastructure, networking, and a
slice of fixed overhead. Revenue is what OpenAI collects from the
user who triggered that response, either directly via subscription
or API fees or indirectly via advertising and licensing. On paid
tiers, the user pays a subscription or per-token fee that exceeds
their inference cost by a comfortable multiple. On the free tier,
the user doesn't pay directly — so revenue has to come from
somewhere else, which until 2026 meant cross-subsidy from paid-tier
profit and now increasingly means advertising.
The interesting metric isn't the average across all users; it's the
gap on each surface separately. A company-wide gross margin number
obscures the fact that some surfaces are extremely profitable and
one surface (the largest by user count) is structurally negative on
direct attribution. Looking at the per-surface picture explains
both why paid tiers compound so well and why advertising became
inevitable.
Where do the lines cross, surface by surface?
Each paid surface clears its inference cost with different margin,
and the gap between cost and revenue tells a different story for
each. Plus runs a comfortable 60–80% gross margin at typical usage.
Pro runs wider at 70–85%, despite heavier average usage, because
the $200 price point absorbs it. Team and Enterprise run the
highest at 70–90%+. API margins vary by endpoint but blend to
55–75%. The free tier inverts the math entirely.
ChatGPT Plus ($20/mo)
Typical Plus user query patterns in 2026 put their monthly
inference cost somewhere between $3 and $8 — well below the $20
subscription price. Gross margin is comfortably positive and
growing as per-query cost falls. Heavy power users can push this
ratio toward break-even or negative at the per-user level, which is
why rate limits exist to cap worst-case exposure. In aggregate,
Plus is gross-margin positive and growing.
ChatGPT Pro ($200/mo)
Even wider margin on average. Pro users get access to more
expensive reasoning models and deeper tool-use envelopes, but $200
per month covers a substantial amount of inference. The exception
is a narrow slice of users who treat Pro as an API replacement and
run reasoning queries at near-limit volume — those users can
compress per-seat margin into single digits, but they're a minority
of the Pro subscriber base. Overall Pro gross margin runs 70–85%.
ChatGPT Team and Enterprise
Enterprise is the margin-heaviest line in the business. Per-seat
pricing ($50–$75+ for Enterprise at mid-volume) reflects
governance, SSO, data handling, and SLA — not raw compute. Most
enterprise users query less intensively than power-user Plus
subscribers because their workloads are concentrated in workday
hours and bounded by organizational rate limits. Revenue-to-cost
ratios are correspondingly high, and Enterprise gross margin runs
75–90%.
OpenAI API
Priced to generate margin on most endpoints. Non-reasoning
GPT-4o-class calls run 65–75% gross margin at list price; reasoning
endpoints (o3, o4-mini) run thinner at 40–55% because reasoning
workloads consume far more compute per response. Fine-tuning jobs
carry their own economics, typically priced to reflect dedicated
capacity costs. In aggregate, API is solidly gross-margin positive
but thinner than the consumer subscription surfaces.
Free tier
This is the surface where the lines cross the wrong way. Revenue
per free user was near zero before the 2026 advertising rollout;
inference cost is small per query (around $0.001–$0.005 on
GPT-4o-class models) but nonzero in aggregate, summing to the high
hundreds of millions to low single-digit billions of dollars
annually. Absent a second revenue engine, the free tier runs at
negative contribution margin and is covered by gross profit from
paid tiers plus the emerging ad line.
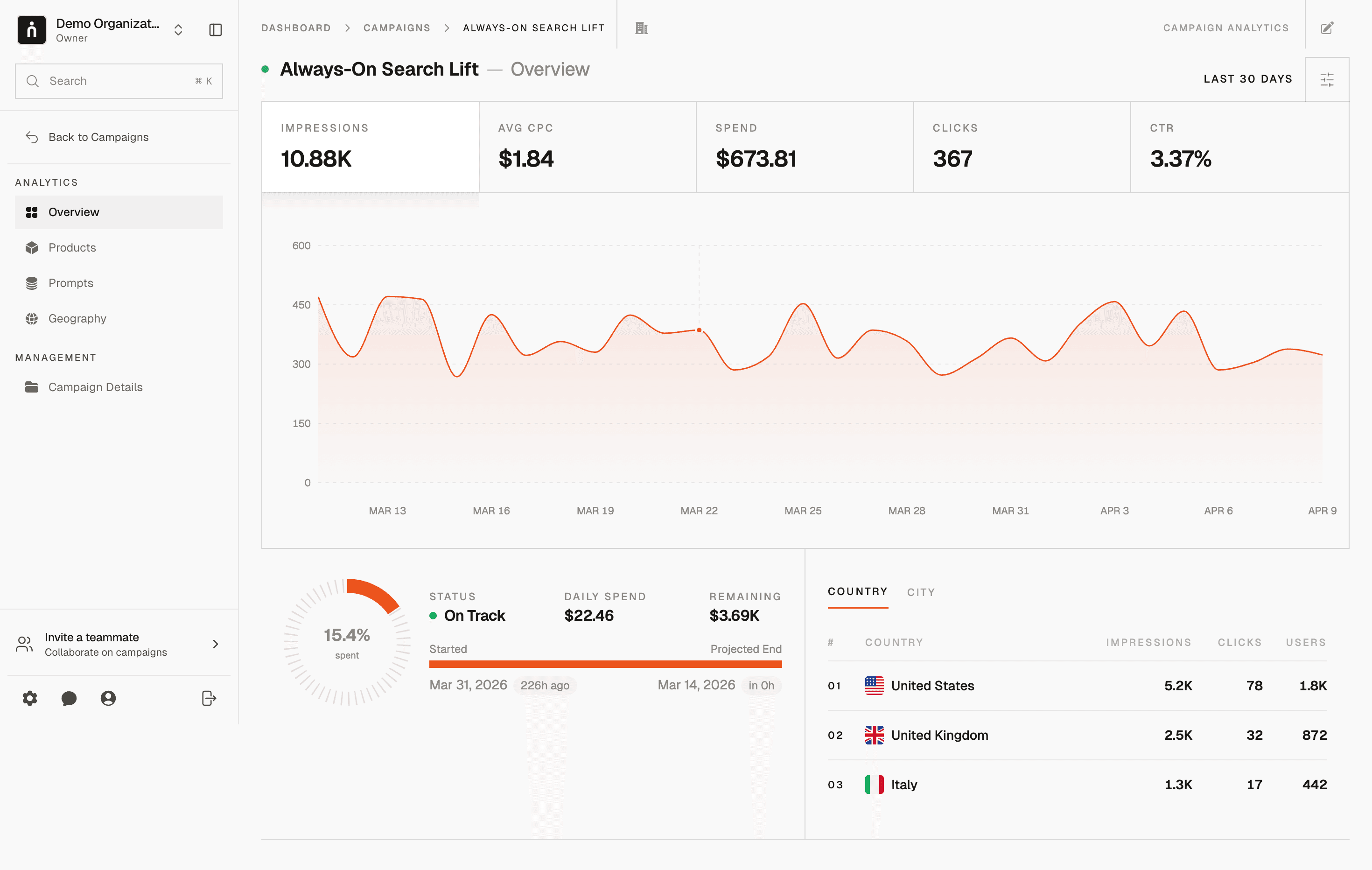
The quantitative picture
Surface | Revenue per user/month | Inference cost profile | Gross margin |
|---|---|---|---|
Free tier | ~$0 (pre-ads) / $0.10–$0.50 (with ads at 2026 ramp) | Small per query, billions in aggregate | Negative → trending to positive |
Plus ($20) | $20 | $3–$8 at typical usage | 60–80% |
Pro ($200) | $200 | $30–$80 at typical usage | 70–85% |
Team ($25–30/seat) | $25–30 | $3–$6 at typical enterprise usage | 75–85% |
Enterprise ($50+/seat) | $50+ | $4–$10 at typical usage | 80–90% |
API | Per-token | Per-token cost below price | 55–75% blended |
Numbers are directional — built from press reporting, published
price sheets, public cost-curve analysis (SemiAnalysis, a16z), and
analyst commentary — not audited OpenAI disclosures. The absolute
numbers should be treated as order-of-magnitude; the relative
ordering across surfaces is robust across sources.
The question isn't whether any ChatGPT product is gross-margin
positive. Most are, and the paid surfaces have been comfortably
positive since 2024. The question is whether the blended
company-wide economics close the gap created by billions of weekly
free queries — and that gap, not subscription pricing, is the
reason advertising became a 2026 priority rather than a 2028
option.
How fast are inference costs actually falling?
Inference cost per query is falling 30–50% annually in 2026, driven
by three compounding forces: hardware generation upgrades,
serving-efficiency improvements, and model distillation. The curve
has flattened from 2023–2024 levels — easier wins are being picked
off — but the improvement pace still outstrips most enterprise
software cost curves by an order of magnitude.
Hardware drives the largest single step-changes. The H100 → H200
transition delivered roughly 40% effective inference cost
reduction at comparable tokens-per-second. The H200 → Blackwell
transition, now ramping in 2026, is expected to deliver another
30–50% depending on workload. Each hardware generation typically
lands with an 18–24 month cadence, so there's one large step per
cycle plus continuous improvements in between.
Serving efficiency delivers the steady background improvement.
Better batching, speculative decoding, KV-cache reuse,
FlashAttention variants, and continuous system-level tuning
contribute a cumulative 10–20% annual cost reduction on top of
hardware. These gains are harder to achieve each year as the stack
matures, but they haven't stopped.
Model distillation compresses capability into smaller, cheaper
models. GPT-4 Turbo → GPT-4o compressed 90%+ of the capability into
a fraction of the compute. GPT-4o → successor distillation
continues that pattern. Distilled models are particularly relevant
to the free tier, where cost-per-query matters more than ceiling
capability.
Inference cost per query has fallen roughly 70–90% between 2023
and 2026 on GPT-4-class capability. That is one of the steepest
cost curves ever observed in a commercial software category — and
it still hasn't closed the free-tier gap, because query volume
grew faster than cost fell.
The compounding dynamic
Two things compound simultaneously, in tension with each other:
Inference cost per query is dropping — roughly 30–50% per
year in 2026, driven by hardware, serving efficiency, and
distillation. This should shrink the free-tier cost line.Free-tier query volume is growing — faster than cost is
falling, as weekly active users expand and per-user query
frequency rises with product maturity.
The net effect: absolute compute spend on the free tier is still
climbing, even as per-query cost falls. Annual free-tier compute
cost in 2026 is estimated larger than 2024's number, despite
per-query cost dropping meaningfully over the same window. This is
the core reason inference efficiency alone doesn't solve the
problem; monetization of free users has to be part of the answer.
The dynamic also matters on the reasoning side. Reasoning models
shift the shape of per-query cost — not just the magnitude.
Extended reasoning generates many internal tokens before producing a
final response, which increases per-query compute by 10–100×
depending on the problem complexity. As reasoning usage grows, the
cost curve for a subset of queries shifts upward even as the
general curve trends down.
What does advertising change in this picture?
Advertising revenue has a specific shape that fits the free-tier
problem precisely: high incremental margin on the ad sale itself,
concentrated on commercial-intent queries (which carry the highest
CPMs), and scales with query volume rather than user count. For the
free tier, this is exactly the right shape — it grows with the cost
it needs to cover.
A free user who sees a labeled sponsored placement on one
commercial-intent query per week generates advertising revenue that
can easily exceed their weekly inference cost across all queries —
turning each free user from a loss into a contribution-positive
user. The leverage comes from CPM differences: commercial-intent
query CPMs can be multiples of the inference cost on that single
query, and the revenue from that one query covers the serving cost
of many other non-commercial queries.
This is the 2026 pivot: advertising doesn't need to dominate
OpenAI's revenue mix to fix the free-tier math. It needs to cover
the serving cost delta, plus some margin for the distribution
value of the free tier. At realistic ramp assumptions —
single-digit percent of free queries showing ads, CPMs in line
with search advertising — it covers that within 12–24 months.
How does the Microsoft compute relationship factor in?
The Microsoft relationship changes the cost-side math in OpenAI's
favor but doesn't eliminate the free-tier gap. Microsoft's capacity
commitments include preferential pricing on Azure compute, which
reduces OpenAI's per-query serving cost materially below retail
Azure rates. The exact discount isn't public, but analyst
reconstruction places it in the 20–50% range off list.
That matters for the gross-margin calculation on every surface.
Paid-tier margins look the way they do partly because Microsoft
supplies compute at below-retail rates. Free-tier cost is smaller
than it would be at list-price Azure compute. If you run the
arithmetic at retail rates, paid-tier margins compress by roughly
10–15 percentage points and the free-tier gap widens.
From an accounting perspective, OpenAI's economics look better with
Microsoft than without. From a strategic perspective, that means
the free-tier gap is larger than the headline numbers suggest — the
pressure to monetize free via advertising is real even with
favorable compute pricing.
What are the common misconceptions?
"The free tier is charity." It isn't — it's a distribution
investment. The free tier creates the user base, training data,
and brand gravity that make every paid surface more valuable.
Eliminating it would collapse paid conversion in ways the direct
cost savings can't compensate for."If inference gets cheap enough, ads become unnecessary." Not
at current growth rates. Query volume is growing faster than
per-query cost is falling, so absolute free-tier spend keeps
rising. Inference efficiency alone doesn't close the gap, and
won't for at least another several years of query-volume growth."Plus subscribers subsidize the free tier." Partially true —
aggregated paid-tier gross profit does cover free-tier cost
today. But that's exactly why advertising is additive, not
replacement: it relieves the subsidy pressure and lets paid-tier
profit flow through to the bottom line rather than funding free
compute."Reasoning models will blow up the cost curve." Overstated.
Reasoning is priced separately on most surfaces, rate-limited on
others, and growing as a percentage of workload but not yet
dominant. It adds pressure at the margin; it doesn't invert the
picture."The API line subsidizes the consumer side." Not really —
the API is a smaller revenue contributor than consumer
subscriptions in aggregate, and its margins are thinner. The
subsidy flow, to the extent there is one, runs from Enterprise
and Pro to free, not from API to consumer.
What comes next?
Three shifts through 2026 and 2027 will redefine the ratio of cost
to revenue on each surface. First, free-tier query mix will shift
toward commercial-intent queries as ChatGPT search becomes a
default behavior — that's good for ad monetization and bad for the
average inference cost per monetized query (commercial-intent
queries tend to be longer). Second, enterprise gross margin will
expand as governance features become commoditized and the seat
count grows against relatively fixed compute overhead. Third,
inference cost curves will continue falling but with diminishing
returns; the next big drop requires Blackwell rolling out at scale
or a serving breakthrough on the software side.
On the revenue side, advertising will grow fastest in percentage
terms. Enterprise will continue compounding in absolute terms at
high rates. Plus and Pro will grow more modestly as consumer
subscription plateaus set in. API will grow steadily as the
developer ecosystem matures. The combined effect: the cost-to-
revenue ratio improves across the board, with the free tier
trending from contribution-negative to contribution-positive on
ad monetization and the paid tiers widening their gross-margin
profile.
How should brands act on this?
For brands, the cost-vs-revenue math is the reason you should take
generative-surface advertising seriously now. The inflection from
"experimental ads" to "scaled labeled placements" is happening on
exactly the timeline the inference-cost math predicted, and
inventory availability on sponsored search and shopping surfaces
will expand through 2026 faster than advertiser demand can absorb
it — which is the window where early CPMs tend to be most
favorable.
The practical steps are measurement, placement discovery, and
activation. Measurement means tracking your brand's citation rate
across ChatGPT answers on your high-value commercial queries —
which is a different metric than search impression share and
requires different instrumentation. Placement discovery means
identifying which commercial queries in your category carry
sponsored inventory today and which will get it next. Activation
means building the operational capability to bid on inventory,
optimize creative, and measure incrementality.
Thrad helps brands prepare for and participate in that shift —
measurement, placement discovery, and activation across ChatGPT,
Perplexity, Gemini, Copilot, and the other surfaces racing through
the same cost curve. The inference-cost trajectory made
advertising inevitable; the question for brands is whether they
move before the inventory gets crowded or after.
chatgpt inference cost, openai revenue per query, free tier economics, llm serving cost, ai unit economics, gpu cost per query, openai gross margin
Citations:
SemiAnalysis, "LLM Serving Cost Curves 2023–2026," 2026. https://semianalysis.com
The Information, "OpenAI product-line P&L disclosures," 2026. https://theinformation.com
Financial Times, "OpenAI free-tier compute cost analysis," 2026. https://ft.com
OpenAI, "ChatGPT Plan Comparison," 2026. https://openai.com/chatgpt
a16z, "State of LLM Inference Economics," 2025. https://a16z.com
Stratechery, "OpenAI's Cost Curves and the Case for Ads," 2026. https://stratechery.com
NVIDIA, "H200 and Blackwell Inference Benchmarks," 2025. https://nvidia.com
Be present when decisions are made
Traditional media captures attention.
Conversational media captures intent.
With Thrad, your brand reaches users in their deepest moments of research, evaluation, and purchase consideration — when influence matters most.
Date Published
Date Modified
Category
Advertising AI
Keyword
chatgpt inference costs vs revenue