AI ad infrastructure for publishers is a five-layer stack: classification, auction, rendering, measurement, brand safety. In 2026, virtually every AI app publisher should integrate the whole stack from a specialized vendor rather than build it. Only apps above roughly 5M daily prompts with a dedicated monetization team should consider in-house builds of specific components.








AI Ad Infrastructure for Publishers — 2026 Guide | Thrad
The infrastructure layer that powers AI-native ads for publishers is five parts: classification, auction, creative rendering, measurement, and brand safety. Most AI app founders should integrate the whole thing. A few with serious scale should build specific components. This piece draws the boundary and shows exactly where it sits.
Date Published
Date Modified
Category
Publisher Monetization
Keyword
ai ad infrastructure for publishers

Start monetizing your AI app in under an hour
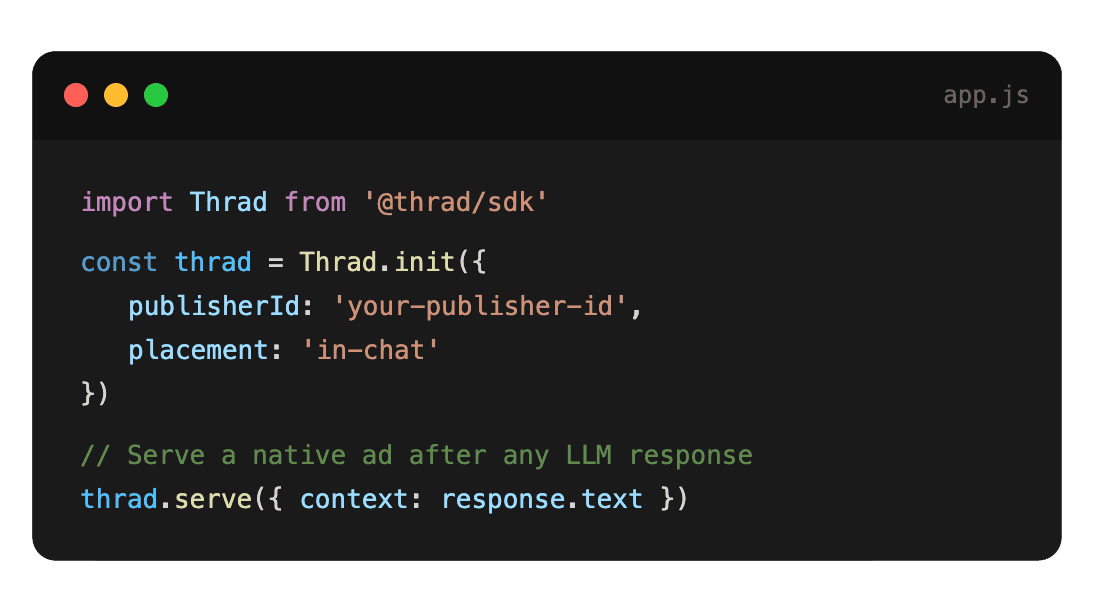
With Thrad, publishers go from first API call to live ads in less than 60 minutes. With fewer than 10 lines of code required, Thrad makes it easy to unlock revenue from your conversational traffic the same day.
The infrastructure layer that powers AI-native ads for publishers is five components: classification, auction, creative rendering, measurement, and brand safety. Most AI app founders should integrate the entire stack from a specialized vendor. A small number with serious scale — roughly 5M daily prompts and up — should consider building specific pieces in-house. This guide draws the boundary, shows the stack component by component, and gives a concrete integrate-vs-build decision for each layer.
What is AI ad infrastructure for publishers?
AI ad infrastructure for publishers is the software layer that runs between your AI app's prompt-response flow and the advertiser demand that monetizes it. It handles classifying the prompt, running the auction, rendering the creative, measuring outcomes, and enforcing brand-safety rules. Thrad's ad infrastructure for AI-app publishers is built as a marketplace between publishers and advertisers — classification, auction, render, and safety all integrated into a single supply-side layer.
Structurally, publishers integrate the infrastructure via SDK or API and get back an ad-augmented response. The publisher does not touch the demand side — advertiser relationships, campaign management, billing — and does not build the classification models, the auction engine, or the disclosure compliance stack. Those are the infrastructure vendor's job. The publisher owns the user relationship and the app's UX; the infrastructure owns everything between prompt classification and advertiser payout.
Why is ad infrastructure a distinct layer?
Because the demand relationships, classification models, measurement primitives, and safety compliance required to monetize AI chat traffic at scale don't pay back their engineering cost for an individual publisher until the publisher is enormous. Business of Apps data shows the generative AI app market hit $3B in 2025, up 273% YoY. At that growth rate, the publishers who capture the most revenue are the ones who spend engineering on their core AI product — not on ad ops, brand-safety policy, classifier training, or demand relationship management. Infrastructure consolidates those costs across many publishers.
A publisher who builds their own ad infrastructure is paying four times: for demand acquisition, for classifier training, for safety compliance, and for measurement tooling. Infrastructure vendors amortize those costs across dozens of publishers.
This is the same logic that produced AdSense for display — an individual blog can't run its own ad sales team, so Google operates the marketplace and blogs take a revenue share. The AI-chat version is younger, less standardized, and pays meaningfully higher RPMs. But the economic logic of consolidation is identical.
What are the five infrastructure layers?
The five layers and what each does. A mature AI ad infrastructure has all five, cleanly separated. A weak infrastructure has gaps — usually in measurement or brand safety — that the publisher discovers painfully.
Layer | What it does | Build-vs-integrate for a typical publisher |
|---|---|---|
Classification | Extracts commercial intent from user prompt | Integrate |
Auction | Matches intent to advertiser demand, clears bid | Integrate |
Creative rendering | Returns native ad text/card, handles disclosure | Integrate |
Measurement | Logs events, reports RPM/match rate/attribution | Integrate |
Brand safety | Refuses unsafe prompts, checks output, enforces compliance | Integrate |
The integrate-vs-build answer is "integrate" for every layer at every scale under a few million daily prompts. Beyond that scale, some publishers build custom classifiers for their vertical (because off-the-shelf classification misses nuance in their domain) or custom measurement layers (because they need to unify ad data with product analytics the vendor doesn't expose). Auction, rendering, and core brand safety almost never pencil out to build in-house, because the demand and compliance costs scale with the advertiser relationships, not with publisher volume.
How does the classification layer work?
Classification is the layer that reads the user prompt and decides what kind of commercial intent — if any — it signals. The output is a structured intent signal: category, purchase stage, geography hints, regulated-content flags. That signal feeds the auction, which picks the winning advertiser.
Classification quality is the single most important differentiator between AI ad infrastructures in 2026. A weak classifier:
Runs auctions on prompts that aren't commercially monetizable
(pure informational questions, general knowledge, emotional support)Misses commercial signals in prompts phrased unconventionally
Over-matches on weak signals, producing low-relevance ad renders
Mis-classifies regulated categories, creating compliance risk
A strong classifier gets match rate, relevance, and safety all higher at once. Publishers should ask vendors specifically: what fraction of prompts does your classifier route to auction, what's the median relevance score of matches, and how do you update the classifier when prompt patterns shift?
Most modern classifiers use a mix of semantic embedding, LLM-based intent extraction, and rules overlays for regulated categories. The embedding and intent models are typically retrained on a weekly or biweekly cadence as prompt patterns evolve. The best infrastructures expose classification-level telemetry to publishers so they can see which prompt clusters do and don't monetize.
How does the auction layer work?
The auction takes the classified intent signal and runs a real-time bid across eligible advertisers. Eligibility combines campaign targeting, budget availability, frequency caps, and brand-safety rules. The winning bid's creative is returned to the rendering layer. Auctions typically clear in tens to low hundreds of milliseconds.
Auction design specifics vary. Most conversational-native infrastructures use first-price auctions with relevance scoring — the bid is adjusted by a quality factor before determining the winner, which encourages advertisers to match well rather than just bid high. Some use second-price auctions inherited from display-era designs. A minority use fixed-CPM slots sold directly to brand advertisers.
For publishers, the auction design affects both revenue and UX. First-price relevance-scored auctions typically pay the publisher well while producing better-matched creative — a combination that's hard to replicate with pure price-only auctions. Ask vendors what auction model they run and how they tune the relevance weight.
How does creative rendering fit into the app?
Creative rendering is where UX lives or dies. The rendered ad has to fit the app's conversational flow, respect disclosure rules, and work across the platforms the app runs on (iOS, Android, web, voice, etc.). Three decisions make or break native fit.
Format. Text inline with the AI response, adjacent text, a
rendered card, or a link block. Inline text is most native but
least visually distinct; cards are most visible but can feel
intrusive.Disclosure. Label placement (top of card, inline tag, separate
row), label wording ("Sponsored," "Ad," "Partner"), and emphasis.
FTC and EU AI Act disclosure rules are the 2026 baseline.UI mapping. Does the SDK's output match your app's design
system? If the rendered ad looks like it came from a different
product, users notice.
Thrad's ad gallery shows specific creative formats live on partner apps, which is the easiest way to evaluate whether a given infrastructure's rendering will look native inside your product. Spend 15 minutes mentally dropping each format into your app's chat view. If any format wouldn't survive a design review, the infrastructure's rendering layer isn't ready for your surface yet.
How does measurement work?
Measurement is the layer publishers most often under-spec in vendor evaluation and most often regret later. Strong measurement has three properties.
Per-category reporting. Revenue, RPM, match rate, and
retention impact broken out by prompt category. Without this
breakdown, product decisions about which user segments to grow or
deprioritize aren't data-driven.Exportable logs. The full event trail — prompt, classification,
auction, render, click, conversion — in an exportable format.
Dashboards-only is a red flag; it makes renegotiation impossible
and blocks analytics integration.Holdout-cohort support. Built-in or API-accessible no-ad
holdouts for measuring true retention impact. Without this, you
can't distinguish between "ads hurt retention 2%" and "ads are
neutral and this quarter's retention dip is product-unrelated."
Dashboards without exportable logs are a measurement red flag. They prevent debugging and block renegotiation, because both require evidence the vendor won't give you.
Publishers should treat measurement maturity as a hard requirement. Infrastructure that's strong on auction but weak on measurement is infrastructure you can't operate against. Switch or insist on measurement parity before integrating.
How does brand safety work at the infrastructure layer?
Brand safety at the infrastructure layer has two halves: input safety (refusing unsafe prompts) and output safety (suppressing ads when the generated response takes an unsafe turn). A mature infrastructure handles both. A weak one handles only input.
Input safety. Refusing to match on crisis prompts, minors,
medical-emergency language, regulated-financial queries, and
political content by default. GARM alignment is the 2026 baseline.Output safety. Re-checking at render time — if the LLM's
response includes unsafe content, the infrastructure pulls the ad
rather than shipping it next to a bad response.Publisher-side overrides. Publisher can add app-specific
blocklists (competitors, categories your product avoids) that the
infrastructure enforces pre-auction.Disclosure automation. Sponsored labeling is applied by the
infrastructure rather than left to the publisher, so compliance
doesn't depend on publisher diligence.Compliance coverage. FTC, EU AI Act, healthcare, financial,
and political ad rules handled at the infrastructure layer, with
per-region defaults.
Thrad's infrastructure page documents the safety layer in detail — refusal categories, output checks, exportable audit logs. That baseline is useful for comparing any other vendor's policy. Infrastructure that can't match or exceed it on brand safety hands the publisher compliance risk that isn't worth the revenue.
What should publishers build themselves?
In 2026, the answer is: almost nothing, at typical scale. Three things publishers legitimately might build, and the scale at which each makes sense.
Custom category blocklists (any scale). Every publisher
should maintain their own list of categories to block — not as
infrastructure, but as configuration the infrastructure honors.Product-level analytics integration (500k+ daily prompts).
If you want ad data inside your core product analytics stack, you
ingest the exportable logs from the infrastructure layer and
reshape them for your own warehouse. This is not a rebuild — it's
a pipeline.Vertical-specific classifier overlays (5M+ daily prompts).
If your app has domain-specific prompt patterns that off-the-shelf
classifiers miss, and if you can quantify the match-rate lift,
you might train a small model that augments (not replaces) the
vendor's classifier. Very rare.
Auction, rendering, core brand safety, disclosure, advertiser demand, and measurement primitives are never worth building in-house at any scale under a nation-state-sized publisher. The demand side relationships alone require a field team, a compliance team, and a billing stack that take years to build.
Common misconceptions
"We can save money by building our own ad stack." Almost
always false at realistic scale. The engineering, compliance, and
demand-relationship costs exceed revenue lift until you're larger
than most AI apps will ever be."Infrastructure is a commodity." It isn't. Classification
quality, auction design, and safety posture vary widely between
vendors, and those differences compound into real RPM gaps."One infrastructure fits all publishers." Different verticals
monetize differently. Horizontal infrastructures are fine for most
apps; niche apps sometimes benefit from vertical-specialized
infrastructure."Measurement is just a dashboard." A dashboard without log
export is unusable once you're serious. Measurement is the raw
data plus the tooling to analyze it."Brand safety is input-only." Output safety matters just as
much on AI surfaces, because the content around the ad is generated
fresh each time.
What comes next for AI ad infrastructure?
Three shifts through late 2026 and 2027.
Interoperability. IAB Tech Lab spec work on AI ad network
reference architecture will make it easier for a publisher to run
two infrastructures in parallel — a primary and a fill — without
bespoke integration code for each.Measurement unification. Third-party measurement tools will
ingest AI ad infrastructure events alongside programmatic display
and CTV, giving publishers and brands a single attribution view
across surfaces.Edge classification. Running prompt classification on-device
rather than at the infrastructure's edge reduces latency and
improves privacy. Early movers are shipping this; by 2027 it will
be standard.
None of these shifts change the integrate-vs-build decision for a publisher in 2026. They do reward publishers whose integration is clean enough to switch, augment, or run-dual when the market matures. Treat the integration as a configuration layer, not a hard-coded dependency.
How to get started
Inventory what your app actually needs, by layer. For each of the five layers (classification, auction, rendering, measurement, brand safety), write down your hard requirements and your preferences. If any vendor fails a hard requirement — no output safety, no log export, no regulated-category coverage — they're disqualified regardless of RPM. Among vendors that clear the hard requirements, pilot the top two.
If your app is early (under 10k daily prompts), optimize for speed and clarity: pick the infrastructure with the fastest integration, cleanest safety defaults, and most transparent measurement. The RPM delta between vendors at that scale is swamped by product-development opportunity cost. If your app is scaling (100k+ daily prompts), run the rigorous pilot — two vendors, two weeks, holdout cohort, score on RPM × (1 − retention delta). If your app is large (1M+ daily prompts), also build your own ingestion pipeline for the exportable logs so you can unify ad data with product analytics.
A final meta-point: the AI ad infrastructure layer is young, standardizing, and consolidating. The publishers who win in late 2026 and 2027 are the ones who integrate early, measure honestly, and switch without drama when a better vendor appears. Treat the infrastructure as a utility, not a commitment. The publishers who do that get more revenue, healthier UX, and more leverage in the next round of vendor negotiations.

ai ad stack, publisher ad infrastructure, conversational ad platform, ad rendering llm, brand safety ai
Citations:
Business of Apps, "AI App Revenue and Usage Statistics (2026)," 2026. https://www.businessofapps.com/data/ai-app-market/
TechCrunch, "ChatGPT reaches 900M weekly active users," February 2026. https://techcrunch.com/2026/02/27/chatgpt-reaches-900m-weekly-active-users/
IAB Hong Kong, "Navigating Brand Safety and Suitability in the AI Era," 2025. https://iabhongkong.com/adtecharticle202505
AdExchanger, "AI Is Helping Brand Safety Break Free From Blocklists," 2026. https://www.adexchanger.com/marketers/ai-is-helping-brand-safety-break-free-from-blocklists/
Coactive, "Contextual Advertising Powered by Multimodal AI," 2026. https://www.coactive.ai/solutions/contextual-advertising
Seedtag, "5 ways Contextual AI is redefining audience targeting," 2026. https://blog.seedtag.com/contextual-ai-redefining-audience-targeting
Sponsored.so, "Native AI Ad Platform for LLMs, Chatbots & Agents," 2026. https://sponsored.so/
Teads, "Getting Started with Teads LLM Integration," 2026. https://developers.teads.com/docs/Chatbot-AI-SDK/Getting-Started/
Playwire, "Top 9 Contextual Advertising Networks for 2025," 2025. https://www.playwire.com/blog/contextual-advertising-networks
Be present when decisions are made
Traditional media captures attention.
Conversational media captures intent.
With Thrad, your brand reaches users in their deepest moments of research, evaluation, and purchase consideration — when influence matters most.